Medieval Media. Special Issue of Seminar: A Journal of Germanic Studies
In recent years, the mediality of premodern and early modern literary and cultural communication has become a focal point in Medieval and Early Modern Studies. Media of transmission, communication, and dissemination have received heightened scrutiny. Scholarship is expanding our understanding of ways in which different kinds of material objects serve as media, and there is renewed interest in the role played by materiality and mediality in the re-circulation, appropriation and adaptation of shared stories, images, and ideas. For a special theme issue of Seminar: A Journal of Germanic Studies, we welcome contributions that take stock of this recent shift in scholarly attention and that probe questions of medieval and early modern mediality from broadly conceived disciplinary and interdisciplinary perspectives. We seek to include contributions from a range of different fields in medieval and early modern studies, drawing on various frameworks and approaches, including: history; art history; literary studies; textual criticism; material studies; architectural history; editorial theory and practice; digital humanities. We are seeking contributions focusing on case studies as well as contributions discussing broader methodological questions.
Lines of inquiry may include:
Please send abstracts of ca. 250 words to both Ann Marie Rasmussen (annmarie.rasmussen@duke.edu) and Markus Stock (markus.stock@utoronto.ca) by January 1, 2015. Decisions on inclusion will be made by February 1, 2015. The due date for the submission of articles will be July 1, 2015. All submissions will be subject to peer-review.
- Orality, writing, print: the simultaneity of medieval and early modern media.
- Text and image reconceptualized as forms of intermediality.
- Types of media material: stone, wood, parchment, wax, metal, voice.
- Relationship between the media’s materiality and the semantics of texts or content more broadly construed.
- Manuscripts as artefacts.
- Rules, types, and situations of media use.
- Histories and concepts of media.
- Mediality in medieval and early modern Catholic religious thought (annunciation, incarnation, sacraments, liturgy).
- Mediality in medieval and early modern Judaism and Protestantism (preaching; reading; use of images).
- The body as medium.
- The charisma of objects.
- Remote communication (messengers, letters etc.).
- Media within media: imitation, representation, and appropriation of different types of media in other media.
- Premodern and early modern multi-media: song, dance, play, images, word, text.
- Spaces and places of media use: court, castle, monastery, church, city houses, city streets, villages, etc.
- The Where of the message: walls, books, bodies, badges, etc.
- Social distribution of media use: media of peasants; burghers; nobles, of members of religious orders, etc.
- Medieval texts and images in contemporary media (comic books; television; computer games; film).
- Modern digital tools offering new research approaches to the medieval past.
Friday, December 12, 2014
CFP: Medieval Media (Special Issue of Seminar: A Journal of Germanic Studies)
There's still more than two weeks left to submit an abstract for a proposed special issue of Seminar that Markus Stock and Ann Marie Rasmussen are putting together. The CFP sounds intriguing, and I think I have something that might fit their project. Now that we've reached the end of the semester, I should have time to work up an abstract.
Friday, December 5, 2014
Online resources for teaching German dialectology
This last semester, I've had the chance to teach a phonetics/introduction to German linguistics course for undergraduate German majors. It's been a fun class. We used the second edition of Sally Johnson and Natalie Braber's Exploring the German Language as the primary textbook, which generally worked well. I found several points needing clarification in the chapter on the history of the German language, but fewer in other chapters.
For teaching about German dialects, I was fortunate to have two native speakers on campus who each came in to talk about their own local dialects and language use. But for class discussion of German dialects, it was a bit tricky to find material that was right for my students (and I'm still looking to add to the collection). Here's a list of things I thought were most useful.
Dialect atlases
Dialect maps
Dialect texts
Videos
Comparison
For teaching about German dialects, I was fortunate to have two native speakers on campus who each came in to talk about their own local dialects and language use. But for class discussion of German dialects, it was a bit tricky to find material that was right for my students (and I'm still looking to add to the collection). Here's a list of things I thought were most useful.
Dialect atlases
- Online Wenker-Atlas. I'm excited to finally have access to the Wenker maps, but the GIS-powered interface can require a lot of time to figure out how the interface works. Some background in Germanic linguistics and information technology is helpful.
- Sprechender Sprachatlas von Bayern. This excellent project was user-friendly enough that I could send my students there and let them work independently. I wish there were similar projects for every German state.
Dialect maps
- Statistik Schweiz. This page from the Swiss government offers several excellent dialect maps of Switzerland, as well as a wealth of other information about Switzerland.
Dialect texts
- tz auf Bairisch. It was surprisingly difficult to find authentic texts that were not poems, proverbs, nineteenth-century literature, or about Christmas. For comprehensible dialect texts for my students, the dialect edition of a local Munich paper was just right.
Videos
- Über 70 Mio. Menschen in Deutschland können kein Bayrisch! A quick and humorous introduction to the topic of dialects. (See also the original public service announcement that it parodies.)
- S'Lebn is a Freid. Also Bavarian, and it offers an interesting contrast between dialect use and non-use.
- Zauberduo Domenico. Another interesting contrast between use of dialect and standard German, this time involving Swiss German.
Comparison
- American English Dialects. This dialect map of North America gives students an idea of American dialect geography.
- NY Times Dialect Quiz. After looking at the static map, it was useful to go through this dialect quiz so that students could see how their personal and family history influenced the regional affiliation of how they spoke.
- The Sounds of German. The old site is still incredibly valuable. Let's hope the site redesign now underway doesn't take anything away from that.
Friday, November 21, 2014
Really early, very small, printed German literature (in the narrow sense)
If you want to look at the literary works that would have been accessible to the broadest range of people in the fifteenth century, then one place to start is with works printed in the vernacular and in smaller formats. In the vernacular, education is less of a barrier, and in the smaller formats (initially defined as broadsides, octavos, and quartos of less than 48 leaves), the economic challenge of acquiring literature is as low as it gets at the time. To look at the market for these works before printing reorganized the market for texts and the medium of the book, it makes sense to look only as late of 1480.
While I'm actually in favor of an expansive definition of literature and an inclusive approach to the objects of literary study, a narrow definition of literature is sometimes pragmatically necessary. We'll eliminate for now saints' lives and other devotional works, and pragmatic and educational texts (including history, current events, and the natural world).
Given those criteria, the resulting bibliography is quite short. It can be succinctly categorized like this:
Narrative works and literary classics
The first two clearly belong together. The Ackermann is an established part of the literary canon, but it's more similar in some ways to the humanist works below. On the other hand, the Ackermann and Pfaffe Amis have a considerable manuscript tradition, while the Pfarrer von Kahlenberg is only known in print.
These end up being the works of just two translators: Heinrich Steinhöwel and Nikolaus von Wyle.
For shorter literary works to 1480, Folz only makes it in by two years, but even in that short time he has too many titles to list.
These are works that might be excluded as devotional or educational works under a narrow definition of literature. As I prefer a broad definition, I'll include them here.
While I'm actually in favor of an expansive definition of literature and an inclusive approach to the objects of literary study, a narrow definition of literature is sometimes pragmatically necessary. We'll eliminate for now saints' lives and other devotional works, and pragmatic and educational texts (including history, current events, and the natural world).
Given those criteria, the resulting bibliography is quite short. It can be succinctly categorized like this:
Narrative works and literary classics
The first two clearly belong together. The Ackermann is an established part of the literary canon, but it's more similar in some ways to the humanist works below. On the other hand, the Ackermann and Pfaffe Amis have a considerable manuscript tradition, while the Pfarrer von Kahlenberg is only known in print.
- Der Stricker, Pfaffe Amis (ca. 1478, GW M4411)
- Philipp Frankfurter, Der Pfarrer von Kahlenberg (ca. 1480, GW 10287)
- Johannes von Tepl, Der Ackermann von Böhmen (1463-1477, GW 193-198)
These end up being the works of just two translators: Heinrich Steinhöwel and Nikolaus von Wyle.
- Heinrch Steinhöwel/Fracesco Petrarca, Griseldis (1470-1480, GW M31576-78, M31580-81, M31583, M3158410, M31597)
- Heinrch Steinhöwel, Apollonius of Tyre (1471, GW 2273)
- Leonardus Aretinus/Nikolaus von Wyle, Guiscardus et Sigismunda (1476, GW 5643, 564210N)
- Aeneas Sylvius Piccolomini/Nikolaus von Wyle, Euryalus et Lucretia (1478, GW M33548)
- Lucian/Nikolaus von Wyle, Der goldene Esel (1477-1480, GW M18985, M18988)
For shorter literary works to 1480, Folz only makes it in by two years, but even in that short time he has too many titles to list.
- Sixteen titles (in seventeen editions) from 1479-80
These are works that might be excluded as devotional or educational works under a narrow definition of literature. As I prefer a broad definition, I'll include them here.
- Die wunderbare Meerfahrt des hl. Brandan (1476, GW 5004)
- Sibyllen Weissagung (1452, 1475; GW M41981, M41983)
- Visio Fulberti (1473, GW 10422)
- Wie Arent Bosman ein Geist erschien (1479, GW 4944)
Friday, November 14, 2014
Georg Meder reads Wilhelm Friess
File this under "things I wish I had seen two years ago."
When writing about prophecies, prognostications, or other sixteenth-century booklets, one naturally wonders who the readers were. (That was the question Xenia von Tippelskirch asked of me and Courtney Kneupper in June at the conference in London about "Dietrich von Zengg.") Usually the only evidence is indirect - who is the printer, what audiences does that printer usually serve, what kinds of demands does the text make on the reader.
But sometimes we have the good fortune of finding someone in the sixteenth century who quotes or cites the work in question. Here, for example, is what Georg Meder says about the second prophecy of Wilhelm Friess in Meder's practica for 1583 (VD16 M 1853, fol. c5r):
For an astrologer, Meder strikes an unusually (but hardly unique) apocalyptic tone. This was not a new development for Meder; one finds similar references in his earlier and alter prognostications. Meder's reading of Wilhelm Friess also appears to begin earlier than 1582. He states in his practica for 1580 (VD16 M 1852, fol. c4r):
Georg Meder is another astrologer about whom not much is known. There are eleven known practicas from him, spanning the years 1577-1599. On the title page, he is described as an astronomer and poet in Kitzingen, and his practica for 1578 (VD16 ZV 22615, fol. a3r) gives Mainbernheim, just south of Kitzingen, as his ancestral origin. The dedications of his practicas suggest a long and difficult search for stable patronage. He dedicated his practica for 1578 to Marggrave Georg Friedrich I of Brandenburg-Ansbach, but for 1579 he dedicated his work to the mayor and city council of Rothenburg ob der Tauber, and to the mayor and city council of Kitzingen the year after that. His practica for 1583 was dedicated to the mayor and city council of Windsheim. For 1597, he dedicated his practica to a lesser nobleman, Johann Fuchs von Dornheim, and for 1599, he refers to a lawyer, Johann Büttner, as his lord and patron. One can't escape the impression of a continuous decline in the status of the patrons to which Meder aspired. His location does not change, however. After his practica for 1577 places him in Dettelsbach, the rest of his practicas give his location as Kitzingen. Meder seems to have been a Lutheran of the Philipist variety, with little good to say about Catholics or Calvinists, while also rejecting the followers of Matthias Flacius.
When writing about prophecies, prognostications, or other sixteenth-century booklets, one naturally wonders who the readers were. (That was the question Xenia von Tippelskirch asked of me and Courtney Kneupper in June at the conference in London about "Dietrich von Zengg.") Usually the only evidence is indirect - who is the printer, what audiences does that printer usually serve, what kinds of demands does the text make on the reader.
But sometimes we have the good fortune of finding someone in the sixteenth century who quotes or cites the work in question. Here, for example, is what Georg Meder says about the second prophecy of Wilhelm Friess in Meder's practica for 1583 (VD16 M 1853, fol. c5r):
Halt auch gentzlich darfür / das derselbige ein gewiser vorbot sein / eines schnellen grossen Kriegsvolcks / so vom Nidergang gegen Mitternacht zuziehen werde / da denn andere mehr Bundsverwandten sich versamlet / und dann mit gemeinem hauffen auff die Berg Israel herein fallen werden. Man lese hievon Wilhelmi Frysii Mastricensis weissagung / so ime von einem Angelo, Anno 77. den 24. Aprilis ist eröffnet worden / und albereit vor lengst in Truck ausgangen ist / und halt hiegegen das 39. und 39. Capitel des Propheten Ezechieleis / und denn auch das 19. und 20. Capitel der Offenbarung Joannis des Evangelisten / so wirdt man endlich befinden / was für jammer sich erheben / und wie Gog und Magog mit all seinem anhang sich wider uns versamlen / und letzlichen nach dem Ezechiele / mit allem solchen grossen hauffen Volcks / vom Himel herab sol nidergelegt und ausgetilget werden. Aber wir Teutschen verachten alle solche warnung / glauben weder den Propheten / noch andern Wunderzeichen / so schier alle tag am Himel und auff Erden sich begeben / ja wol auch den Engeln nicht / und solchs am meisten dise / so andere zu bus vermanen solten. Derhalben wir anders nichts / denn endlichen uberfals Gog und magogs zugewarten haben.From the date that Meder cites, it's clear that he had read one of the Basel editions printed by Samuel Apiarius, or a copy of one of those editions, probably printed in 1577. Prior editions attribute the vision to 1574, and later ones change the month and year.
For an astrologer, Meder strikes an unusually (but hardly unique) apocalyptic tone. This was not a new development for Meder; one finds similar references in his earlier and alter prognostications. Meder's reading of Wilhelm Friess also appears to begin earlier than 1582. He states in his practica for 1580 (VD16 M 1852, fol. c4r):
[Because of various eclipses and comets,] weiß ich anders nichts zu iudicirn, denn was in fertiger Practica vermeldet / nemlich das ein Occidentischer Potentat / mit hülff etzlicher mitternechtigen und Orientischen Monarhen von mitternacht hero ein unzelich Volck zusammen bringen / und auff die berg Israhel herein fallen / und deß heerlager der heiligen umbringen werden. [Read Ezechiel 38-39 and Revelation 18-19; those who cause this bloodbath will have their reward.] Denn was einmal der liebe Gott von diser grossen und letzten Niderlag und feldschlacht (deren gleiche keine von anfang der welt niemals sich begeben hat) durch seine lieben Propheten und Apostel zuvor verkündiget / wirdt zu diser jetzigen Zeit gewißlich erfüllet werden müssen / wie dann hievon auch neulich ein Prophecey außgangen / in Belgico beschehen / hievon genugsame Zeugniß gibt / und wir gewißlich bessers nichts zu erwarten haben.The combination of ideas and sources in both practicas is nearly identical, so that it seems that the "Belgian prophecy" is none other than that of Wilhelm Friess of Maastricht. In his practica for 1579 (VD16 M 1851, fol. e4v), Meder explicitly identifies the mountain: "auff den Bergen Israhel / das ist / (wie es denn von allen außgelegt wirdt) in Germania."
Georg Meder is another astrologer about whom not much is known. There are eleven known practicas from him, spanning the years 1577-1599. On the title page, he is described as an astronomer and poet in Kitzingen, and his practica for 1578 (VD16 ZV 22615, fol. a3r) gives Mainbernheim, just south of Kitzingen, as his ancestral origin. The dedications of his practicas suggest a long and difficult search for stable patronage. He dedicated his practica for 1578 to Marggrave Georg Friedrich I of Brandenburg-Ansbach, but for 1579 he dedicated his work to the mayor and city council of Rothenburg ob der Tauber, and to the mayor and city council of Kitzingen the year after that. His practica for 1583 was dedicated to the mayor and city council of Windsheim. For 1597, he dedicated his practica to a lesser nobleman, Johann Fuchs von Dornheim, and for 1599, he refers to a lawyer, Johann Büttner, as his lord and patron. One can't escape the impression of a continuous decline in the status of the patrons to which Meder aspired. His location does not change, however. After his practica for 1577 places him in Dettelsbach, the rest of his practicas give his location as Kitzingen. Meder seems to have been a Lutheran of the Philipist variety, with little good to say about Catholics or Calvinists, while also rejecting the followers of Matthias Flacius.
Friday, November 7, 2014
Astrological prognostications and Bildungsniveaulimbo in the sixteenth century
Now that I've had a chance to check about half of the facsimiles that I discovered, have I found anything interesting? Yes, yes I have.
One of the constitutive features of practicas, or annual astrological prognostic booklets, is how they identify themselves as a reduced version of some other text. The genre as a whole defines itself as the specific and concrete application of theoretical texts, but practicas also describe themselves as reduced versions of other works. Johannes von Glogau, the first German astrologer whose practicas appeared in print, regularly referred the readers of his Latin prognosticastions to another work for the complete astrological argumentation, usually with a phrase such as Horum omnium cause patent in iudicio maiori. Georg Tannstetter made reference to such a work as late as 1523, but by then most astrologers had switched to referring readers not from a smaller to a larger work, but from a German to a Latin work for the complete astrological reasoning. Interestingly, these longer works with more extensive reasoning do not seem to have been published, and one may wonder if they actually existed. While there are many practicas that were published in both Latin and German translation, the astrological argumentation is usually similar in both. So for their authority, practicas often direct the reader to other texts that are nearly unattainable, if they exist at all.
Even eight-leaf vernacular astrological booklets did not constitute the extreme low end of popular versus learned, however. One of the facsimiles I found this week is VD16 H 3291, an extract from the practica for 1548 of Simon Heuring (see the facsimile here). Looking through VD16, this work appears to be unique, as I don't find any other similar extracts from annual prognostications. Comparing its text to Heuring's complete German practica for 1548 (VD16 H 3290), the extract is clearly based on the complete practica, but the text has been radically shortened. Compare the first sections of each; shared material from the complete practica is underlined, while new or added words in the extract are in bold.
It's noteworthy that the extract includes two sections, on human fates and on cities or regions, that do not appear as chapters in Heuring's complete practica. The texts are drawn from his chapter on illness, but are moved to new sections following the section on war. This is exactly where human fates and geographical areas would typically be treated in practicas, for example in those of Johannes Virdung. Heuring's preface, on the other hand, disappears entirely.
From the comparison of the text and other features of just these two editions, we can get a sense of steps that sixteenth-century editors took to adapt texts to less educated and less practiced readers:
* * *
One of the constitutive features of practicas, or annual astrological prognostic booklets, is how they identify themselves as a reduced version of some other text. The genre as a whole defines itself as the specific and concrete application of theoretical texts, but practicas also describe themselves as reduced versions of other works. Johannes von Glogau, the first German astrologer whose practicas appeared in print, regularly referred the readers of his Latin prognosticastions to another work for the complete astrological argumentation, usually with a phrase such as Horum omnium cause patent in iudicio maiori. Georg Tannstetter made reference to such a work as late as 1523, but by then most astrologers had switched to referring readers not from a smaller to a larger work, but from a German to a Latin work for the complete astrological reasoning. Interestingly, these longer works with more extensive reasoning do not seem to have been published, and one may wonder if they actually existed. While there are many practicas that were published in both Latin and German translation, the astrological argumentation is usually similar in both. So for their authority, practicas often direct the reader to other texts that are nearly unattainable, if they exist at all.
Even eight-leaf vernacular astrological booklets did not constitute the extreme low end of popular versus learned, however. One of the facsimiles I found this week is VD16 H 3291, an extract from the practica for 1548 of Simon Heuring (see the facsimile here). Looking through VD16, this work appears to be unique, as I don't find any other similar extracts from annual prognostications. Comparing its text to Heuring's complete German practica for 1548 (VD16 H 3290), the extract is clearly based on the complete practica, but the text has been radically shortened. Compare the first sections of each; shared material from the complete practica is underlined, while new or added words in the extract are in bold.
| VD16 H 3290 | VD16 H 3291 |
| Das Erst Capitel / Von den Planeten so diß 48. Jar regieren und herschen werden. | Von Regierung der Planeten. |
| Auß dem Lauff aller Planetenn / Auch eingang der Sonnenn in die 4. Angel. zeichen / Als da sindt der Wider / Kreps / Wag / unnd Steinbock erlernenn wir / Das in disem 48. Jar abermals Saturnus am geweltigsten sein / Und mit hinwegnemen viler waydlichen leut / Das fürnembst Regiment habenn sol / Mit welchem sehr der gütig Jupiter lauffen / Unnd sein wütenn etwas wirdt miltern wöllenn / Das dieweil er so gar / Nicht allein für sich selbest / Sonder auch auß krafft der grossenn Finsternuß / Darzu der andern Constellation krefftig / Wenig schaffenn / Dieweil der mars das Zaichenn auch darzu thon / Unnd mit Saturno in sterblicher und blutdürstigender art / einreissenn wird / Gott der almechtig wöll ein genediges einsehen haben / das doch nicht so gar grosser unradt / als höhlich zubesorgen / wie und zum teil gantz wol verdient / volge. | In disem Acht und viertzigisten Jar / wird abermals Saturnus / das fürnembst Regiment haben / unnd vil tapffere Leütte hinweg nemen. Unnd wiewol der gütig Jupiter / sein wüten etwas zu miltern begert / So wirdt doch der grimmig Mars / dem Saturno zu hilff / mit sterblicher und blůtdürstiger art / einreyssen. |
It's noteworthy that the extract includes two sections, on human fates and on cities or regions, that do not appear as chapters in Heuring's complete practica. The texts are drawn from his chapter on illness, but are moved to new sections following the section on war. This is exactly where human fates and geographical areas would typically be treated in practicas, for example in those of Johannes Virdung. Heuring's preface, on the other hand, disappears entirely.
From the comparison of the text and other features of just these two editions, we can get a sense of steps that sixteenth-century editors took to adapt texts to less educated and less practiced readers:
- larger type face
- fewer lines of text per page
- smaller text blocks
- clearer distinction between texts and paratexts
- simpler syntax, reduction in dependent clauses
- explicit marking of sentence breaks
- more certainty in statements about the future, less hedging or ambiguity
- switch from numbered chapters to topical sections
- more traditional organization of topics
- reduction of metadiscourse
Friday, October 31, 2014
Word, Zotero, Excel, Perl and back: online facsimiles and the digital research process in the humanities (with source code)
At a recent conference on book history and digital humanities in Wolfenbüttel, I was struck by the very different places the presenters were in with respect to adopting digital tools. Some presenters did little more than write their papers using Word, some made use of bleeding-edge visualization tools, and others were everywhere in between. One is not necessarily better than the others, as long as the appropriate tools are being used for the task - some projects just don't require complex visualization strategies. While watching the presentations, it occurred to me that selecting digital tools for my own research is like peeling back the layers of an onion.
 For the simplest research projects, Word is enough for taking notes and then turning those notes into a written text. When I write book reviews, for example, I rarely need anything more than Word.
For the simplest research projects, Word is enough for taking notes and then turning those notes into a written text. When I write book reviews, for example, I rarely need anything more than Word.
 For more complex projects, I use Zotero to manage notes and bibliography, and for creating footnotes. For my forthcoming article on Lienhard Jost, I took several pages of notes in Word. Then I created a subcollection in Zotero that held a few dozen bibliographical sources, some with child notes. When I started writing, I used Zotero to create all the footnotes.
For more complex projects, I use Zotero to manage notes and bibliography, and for creating footnotes. For my forthcoming article on Lienhard Jost, I took several pages of notes in Word. Then I created a subcollection in Zotero that held a few dozen bibliographical sources, some with child notes. When I started writing, I used Zotero to create all the footnotes.
 If I have a significant amount of tabular data, however, of if I need to do any calculation, then Excel becomes an essential tool for analysis and information management. If I'm working with more than five or ten editions, I'll create a spreadsheet to keep track of them. For a joint article in progress on "Dietrich von Zengg," I have notes from Word, a Zotero subcollection to manage bibliography and additional notes, and an Excel spreadsheet of 20+ relevant editions (including among other things the date and place of printing, VD16 number, and whether I have a facsimile or not). For establishing the textual history, I start with Word, but I need Excel to keep track of all the variants. I use Zotero again for footnotes as I write the article in Word.
If I have a significant amount of tabular data, however, of if I need to do any calculation, then Excel becomes an essential tool for analysis and information management. If I'm working with more than five or ten editions, I'll create a spreadsheet to keep track of them. For a joint article in progress on "Dietrich von Zengg," I have notes from Word, a Zotero subcollection to manage bibliography and additional notes, and an Excel spreadsheet of 20+ relevant editions (including among other things the date and place of printing, VD16 number, and whether I have a facsimile or not). For establishing the textual history, I start with Word, but I need Excel to keep track of all the variants. I use Zotero again for footnotes as I write the article in Word.
 Once I have more than several dozen primary sources, however, neither Excel nor Zotero are sufficient, especially if I need to look at subsets of the primary sources. For Printing and Prophecy, I made a systematic search of GW/ISTC/VD16 for relevant printed editions before 1550 (extended to 1620 for an article I published in AGB), then entered all the information into an Access database. It took months of daily data-entry, and I still update the database whenever I come across something that sounds relevant. For my work now, it's a huge time-saver. If I want to know what prophetic texts were printed in Nuremberg between 1530 and 1540, it takes me about ten seconds to find out, and I can also create much more complex queries. Or if I'm planning to visit Wolfenbüttel and want to find out which printed editions in the Herzog August Bibliothek I've never seen in person or in facsimile, a database search will send me in the right direction. I'll also import tabular data into Access and export tables from Access into Excel based on particular queries, such as the table of all editions attributed to Wilhelm Friess. The Strange and Terrible Visions was an Excel project, but Printing and Prophecy was driven by Access.
Once I have more than several dozen primary sources, however, neither Excel nor Zotero are sufficient, especially if I need to look at subsets of the primary sources. For Printing and Prophecy, I made a systematic search of GW/ISTC/VD16 for relevant printed editions before 1550 (extended to 1620 for an article I published in AGB), then entered all the information into an Access database. It took months of daily data-entry, and I still update the database whenever I come across something that sounds relevant. For my work now, it's a huge time-saver. If I want to know what prophetic texts were printed in Nuremberg between 1530 and 1540, it takes me about ten seconds to find out, and I can also create much more complex queries. Or if I'm planning to visit Wolfenbüttel and want to find out which printed editions in the Herzog August Bibliothek I've never seen in person or in facsimile, a database search will send me in the right direction. I'll also import tabular data into Access and export tables from Access into Excel based on particular queries, such as the table of all editions attributed to Wilhelm Friess. The Strange and Terrible Visions was an Excel project, but Printing and Prophecy was driven by Access.
 For projects that require very specific or complex analysis, or that involve online interaction, Access is not the right tool for me. To create the Access database for "The Shape of Incunable Survival and Statistical Estimation of Lost Editions," I spent several hours writing Perl scripts to query the ISTC and analyze the results. Every so often I'll need to write a new Perl script to extend one of the Access databases that I work with. (One doesn't have to use Perl, of course. Oliver Duntze's presentation involved some very interesting work on typographic history using Python. R and other statistical packages probably belong here, too.)
For projects that require very specific or complex analysis, or that involve online interaction, Access is not the right tool for me. To create the Access database for "The Shape of Incunable Survival and Statistical Estimation of Lost Editions," I spent several hours writing Perl scripts to query the ISTC and analyze the results. Every so often I'll need to write a new Perl script to extend one of the Access databases that I work with. (One doesn't have to use Perl, of course. Oliver Duntze's presentation involved some very interesting work on typographic history using Python. R and other statistical packages probably belong here, too.)
Problem: As I'm located a few thousand miles from most of my primary sources, digital facsimiles have become especially important to my work. I check several digitization projects daily for new facsimiles and update my database accordingly. Systematic searching for facsimiles led me to the discovery Lienhard Jost's lost visions, so I've already seen real professional benefit from keeping track of new digital editions. But what if I miss a day or skip over an important title? I might be missing out on something important.
Solution: Create an Access query to check my database and find all the titles in VD16 for which no facsimile is known. Time: 10 seconds. Result: 1,565 editions.
Export the results to Excel, and save them as a text file. Time: 10 more seconds.
Search VD16 for all 1,565 editions by hand and check for new facsimiles? Time: 13 mind-numbing hours?
No.
Instead, write a short Perl script (see below) to read the text file, query the VD16 database, and spit out the VD16 numbers when it finds a link to a digital edition. Time: 1 hour (30 minutes programming, 30 minutes run time). Result: 280 new digital facsimiles that I had overlooked.
To inspect all of those facsimiles and see if they're hiding anything exciting will take a few weeks, but most of the time I spend on it will involve core scholarly competencies of reading and evaluating primary sources, and it will make my knowledge of the sources more comprehensive and complete. In cases like this, digital tools let me get to the heart of my scholarship more efficiently and spend less time on repetitive tasks.
Does every humanist need to know a programming language, as some conference participants suggested? I don't know. We need to constantly acquire or become conversant in new skills, both within and outside our discipline, but sometimes it makes more sense to rely on the help of experts. I don't think it's implausible, however, that before long it will be as common for scholars in the humanities to use programming languages as it is for us to use Excel today.
After all, if you can learn Latin, Perl isn't difficult.
### This script reads through a list of VD16 numbers (assumed to be named 'vd16.txt' and found in the same directory where the
### script is run, with one entry on each line in the form 'VD16 S 843'). The script loads the corresponding VD16 entry and checks
### to see if a digital facsimile is available. If it is, it prints the VD16 number.
### This script relies on the following Perl modules: LWP
use strict;
use LWP::Simple; ### For grabbing web pages
my $VD16number;
my $url;
my $baseurl = 'http://gateway-bayern.de/';
my $VD16page;
my $formatVD16number;
open FILE , "<VD16.txt";
while (<FILE>) {
### Create the URL to check
($VD16number) = ($_);
### Remove the newlines
chomp ($VD16number);
### Replace spaces with + signs for the durable URL (seems not to be strictly necessary, will accept spaces OK)
$formatVD16number = $VD16number;
$formatVD16number =~ s/[ ]/+/g;
### Set up the URL we want to retrieve
$url = $baseurl . $formatVD16number;
### Now load that page
$VD16page = get $url;
### Now look for a facsimile link
if ($VD16page =~ /nbn-resolving.de/) {
### If we find one, print the VD16 number
print "$VD16number\n";
}
}
* * *
Problem: As I'm located a few thousand miles from most of my primary sources, digital facsimiles have become especially important to my work. I check several digitization projects daily for new facsimiles and update my database accordingly. Systematic searching for facsimiles led me to the discovery Lienhard Jost's lost visions, so I've already seen real professional benefit from keeping track of new digital editions. But what if I miss a day or skip over an important title? I might be missing out on something important.
Solution: Create an Access query to check my database and find all the titles in VD16 for which no facsimile is known. Time: 10 seconds. Result: 1,565 editions.
Export the results to Excel, and save them as a text file. Time: 10 more seconds.
Search VD16 for all 1,565 editions by hand and check for new facsimiles? Time: 13 mind-numbing hours?
No.
Instead, write a short Perl script (see below) to read the text file, query the VD16 database, and spit out the VD16 numbers when it finds a link to a digital edition. Time: 1 hour (30 minutes programming, 30 minutes run time). Result: 280 new digital facsimiles that I had overlooked.
To inspect all of those facsimiles and see if they're hiding anything exciting will take a few weeks, but most of the time I spend on it will involve core scholarly competencies of reading and evaluating primary sources, and it will make my knowledge of the sources more comprehensive and complete. In cases like this, digital tools let me get to the heart of my scholarship more efficiently and spend less time on repetitive tasks.
Does every humanist need to know a programming language, as some conference participants suggested? I don't know. We need to constantly acquire or become conversant in new skills, both within and outside our discipline, but sometimes it makes more sense to rely on the help of experts. I don't think it's implausible, however, that before long it will be as common for scholars in the humanities to use programming languages as it is for us to use Excel today.
* * *
After all, if you can learn Latin, Perl isn't difficult.
### This script reads through a list of VD16 numbers (assumed to be named 'vd16.txt' and found in the same directory where the
### script is run, with one entry on each line in the form 'VD16 S 843'). The script loads the corresponding VD16 entry and checks
### to see if a digital facsimile is available. If it is, it prints the VD16 number.
### This script relies on the following Perl modules: LWP
use strict;
use LWP::Simple; ### For grabbing web pages
my $VD16number;
my $url;
my $baseurl = 'http://gateway-bayern.de/';
my $VD16page;
my $formatVD16number;
open FILE , "<VD16.txt";
while (<FILE>) {
### Create the URL to check
($VD16number) = ($_);
### Remove the newlines
chomp ($VD16number);
### Replace spaces with + signs for the durable URL (seems not to be strictly necessary, will accept spaces OK)
$formatVD16number = $VD16number;
$formatVD16number =~ s/[ ]/+/g;
### Set up the URL we want to retrieve
$url = $baseurl . $formatVD16number;
### Now load that page
$VD16page = get $url;
### Now look for a facsimile link
if ($VD16page =~ /nbn-resolving.de/) {
### If we find one, print the VD16 number
print "$VD16number\n";
}
}
Friday, October 24, 2014
Let's learn R: Confidence intervals, and the "So what?" question for history and literary studies
To catch up with the last two posts (one, two): In 2007, Goran Proot and Leo Egghe published an article in Papers of the Bibliographical Society of America (102: 149-74) in which they suggested a method for estimating the number of missing editions of printed works based on surviving copies. In 2008, Quentin Burrell (in Journal of Informetrics 2:101-5) showed that their approach was a special case of the unseen species problem, which has been widely studied in statistics, and suggested a more robust approach based on the statistical literature. The problem is that applying Proot and Egghe's method is within the abilities of most book historians, while applying Burrell's is not. The last few posts have been dedicated to implementing Burrell's approach in R and bringing it within reach of the non-statistician.
The specific estimate that Burrell's method offers is not substantially different from Proot and Egghe's. Burrell's approach does offer two important advantages, however. The first is a confidence interval: within what range are we 95% confident that the actual number of lost or total editions lies? Burrell offers the following formula, where n is the number of editions (804 in Proot and Egghe's data):

This formula in turn relies on the formula for the Fisher information of a truncated Poisson distribution, which Burrell derives for us:

This again looks fearsome, but all we have to do is plug the right numbers into R, with e = Euler's number and λ = .2461 (as we found last time).
Let's define i according to Burrell's equation (5):
> i=(1-(1+.2461)*exp(1)^-.2461)/(.2461*(1-exp(1)^-.2461)^2)
> i
[1] 2.198025
So according to Burrell's equation (4), the confidence interval is .2461 plus or minus the result of this:
> 1.96/(sqrt(804*i))
[1] 0.04662423
Or in other words,
> .2461-1.96/(sqrt(804*i))
[1] 0.1994758
> .2461+1.96/(sqrt(804*i))
[1] 0.2927242
So we expect that there is a 95% chance that the actual fraction of missing editions lies somewhere between .7462 and .8192, which we find in the same way as mentioned in the last post, which also lets us estimate a range for the number of total editions:
> exp(-.1994758)
[1] 0.81916
> exp(-.2927242)
[1] 0.7462279
> 804/(1-exp(-.1994758))
[1] 4445.92
> 804/(1-exp(-.2927242))
[1] 3168.197
The second advantage of using Burrell's method is of fundamental importance: It forces us to think about when we can apply it, and when we can't. We can observe both numerically and graphically that Proot and Egghe's data are a very good fit for a truncated Poisson distribution, and therefore plug numbers into Burrell's equations with a clean conscience. (NB: I have stated in print that a truncated Poisson distribution is a very poor fit for modelling incunable survival, and I think it will usually be a poor model for most situations involving book survival. What to do about that is a problem that still needs to be addressed.)
In addition, Burrell offers a statistical test of how well the truncated Poisson distribution fits the observed data. Burrell's Table 1 compares the observed and the expected number of editions with the given number of copies, to which he applies a chi-square test for goodness of fit. Note, however, that a rule of thumb for chi-square tests is that no category should have five or less observations, and so Burrell combines the number of 3-, 4-, and 5-copy editions into one category.
Can R do this? Of course it can. R was made to do this.
> observed <- c(714,82,8)
> expected <- c(709.11,87.27,7.62)
> chisq.test (observed, p=expected, rescale.p=TRUE)
Chi-squared test for given probabilities
data: observed
X-squared = 0.3709, df = 2, p-value = 0.8307
So we derive nearly the same chi-squared value as Burrell does, .371 compared to his .370. My quibble with Burrell is that I can't see how there can be only 1 degree of freedom (df), as Burrell says, rather than 2, or .89 for a p-value rather than .831. The chi-squared value can be anything from zero (for a perfect fit) on up (for increasingly poor fits), while the degrees of freedom is defined as the number of categories (which here are the 1-copy editions, 2-copy editions, or 3/4/5-copy editions) minus one. The p-value ranges from very small (for a terrible fit) up to 1 (for a perfect fit). There is a great deal written about how to apply and interpret the results of a chi-square or other statistical tests, but the values above support the visual impression, as Burrell notes, that Proot and Egghe's data is a very close fit to a truncated Poisson distribution.
So why should a book historian or scholar of older literature care about any of this? Stated very briefly, the answer is:
For studying older literature, we often implicitly assume that what we can find in libraries today reflects what could have been found in the fifteenth or sixteenth centuries, and that manuscript catalogs and bibliographies of early printing are a reasonably accurate map of the past. But we need to have a clearer idea of what we don't know. We need to understand what kinds of books are most likely to disappear without a trace.
For book history, the question of incunable survival has been debated for over a century, with the consensus opinion holding until recently that a small fraction of editions are entirely unknown. It now seems clear that the consensus view is not correct.
For over seventy years, the field of statistics has been working on ways to provide estimates of unobserved cases, the "unseen species problem." The information that the statistical methods require - the number of editions and copies - is information that can be found, with some effort, in bibliographic databases. The ISTC, GW, VD16, and others are coming closer to providing a complete census and a usable copy count for each edition.
Attempts to estimate lost editions from within the field of book history have taken place independently of the statistical literature. This has only recently begun to change. Quentin Burrell's 2008 article made an important contribution to moving the discussion forward, and he challenged those studying lost books to make use of the method he outlined.
Statistical arguments are difficult for scholars in the humanities to follow, however, and the statistical methods Burrell suggested are difficult for scholars in the humanities to implement. The algebraic formula offered by Proot and Egghe is much more accessible - but limited. We have a statistical problem on our hands, and making progress requires engaging with the statistical arguments.
We can do it. We have to understand the concepts, but humanists are good at grappling with abstractions. We can use R to handle the calculations. These three posts on R and Burrell provide all we need in order to turn copy counts into an estimation of lost editions along with confidence intervals and a test of goodness of fit. Every part of the more robust approach suggested by Burrell is now implemented in R. We could write a script to automate the whole process. This doesn't solve all our problems - there's the problem of most kinds of book survival not being good fits for a Poisson distribution - but it at least gets us caught up to 2008.
The specific estimate that Burrell's method offers is not substantially different from Proot and Egghe's. Burrell's approach does offer two important advantages, however. The first is a confidence interval: within what range are we 95% confident that the actual number of lost or total editions lies? Burrell offers the following formula, where n is the number of editions (804 in Proot and Egghe's data):
This formula in turn relies on the formula for the Fisher information of a truncated Poisson distribution, which Burrell derives for us:
This again looks fearsome, but all we have to do is plug the right numbers into R, with e = Euler's number and λ = .2461 (as we found last time).
Let's define i according to Burrell's equation (5):
> i=(1-(1+.2461)*exp(1)^-.2461)/(.2461*(1-exp(1)^-.2461)^2)
> i
[1] 2.198025
So according to Burrell's equation (4), the confidence interval is .2461 plus or minus the result of this:
> 1.96/(sqrt(804*i))
[1] 0.04662423
Or in other words,
> .2461-1.96/(sqrt(804*i))
[1] 0.1994758
> .2461+1.96/(sqrt(804*i))
[1] 0.2927242
So we expect that there is a 95% chance that the actual fraction of missing editions lies somewhere between .7462 and .8192, which we find in the same way as mentioned in the last post, which also lets us estimate a range for the number of total editions:
> exp(-.1994758)
[1] 0.81916
> exp(-.2927242)
[1] 0.7462279
> 804/(1-exp(-.1994758))
[1] 4445.92
> 804/(1-exp(-.2927242))
[1] 3168.197
The second advantage of using Burrell's method is of fundamental importance: It forces us to think about when we can apply it, and when we can't. We can observe both numerically and graphically that Proot and Egghe's data are a very good fit for a truncated Poisson distribution, and therefore plug numbers into Burrell's equations with a clean conscience. (NB: I have stated in print that a truncated Poisson distribution is a very poor fit for modelling incunable survival, and I think it will usually be a poor model for most situations involving book survival. What to do about that is a problem that still needs to be addressed.)
In addition, Burrell offers a statistical test of how well the truncated Poisson distribution fits the observed data. Burrell's Table 1 compares the observed and the expected number of editions with the given number of copies, to which he applies a chi-square test for goodness of fit. Note, however, that a rule of thumb for chi-square tests is that no category should have five or less observations, and so Burrell combines the number of 3-, 4-, and 5-copy editions into one category.
Can R do this? Of course it can. R was made to do this.
> observed <- c(714,82,8)
> expected <- c(709.11,87.27,7.62)
> chisq.test (observed, p=expected, rescale.p=TRUE)
Chi-squared test for given probabilities
data: observed
X-squared = 0.3709, df = 2, p-value = 0.8307
So we derive nearly the same chi-squared value as Burrell does, .371 compared to his .370. My quibble with Burrell is that I can't see how there can be only 1 degree of freedom (df), as Burrell says, rather than 2, or .89 for a p-value rather than .831. The chi-squared value can be anything from zero (for a perfect fit) on up (for increasingly poor fits), while the degrees of freedom is defined as the number of categories (which here are the 1-copy editions, 2-copy editions, or 3/4/5-copy editions) minus one. The p-value ranges from very small (for a terrible fit) up to 1 (for a perfect fit). There is a great deal written about how to apply and interpret the results of a chi-square or other statistical tests, but the values above support the visual impression, as Burrell notes, that Proot and Egghe's data is a very close fit to a truncated Poisson distribution.
* * *
So why should a book historian or scholar of older literature care about any of this? Stated very briefly, the answer is:
For studying older literature, we often implicitly assume that what we can find in libraries today reflects what could have been found in the fifteenth or sixteenth centuries, and that manuscript catalogs and bibliographies of early printing are a reasonably accurate map of the past. But we need to have a clearer idea of what we don't know. We need to understand what kinds of books are most likely to disappear without a trace.
For book history, the question of incunable survival has been debated for over a century, with the consensus opinion holding until recently that a small fraction of editions are entirely unknown. It now seems clear that the consensus view is not correct.
For over seventy years, the field of statistics has been working on ways to provide estimates of unobserved cases, the "unseen species problem." The information that the statistical methods require - the number of editions and copies - is information that can be found, with some effort, in bibliographic databases. The ISTC, GW, VD16, and others are coming closer to providing a complete census and a usable copy count for each edition.
Attempts to estimate lost editions from within the field of book history have taken place independently of the statistical literature. This has only recently begun to change. Quentin Burrell's 2008 article made an important contribution to moving the discussion forward, and he challenged those studying lost books to make use of the method he outlined.
Statistical arguments are difficult for scholars in the humanities to follow, however, and the statistical methods Burrell suggested are difficult for scholars in the humanities to implement. The algebraic formula offered by Proot and Egghe is much more accessible - but limited. We have a statistical problem on our hands, and making progress requires engaging with the statistical arguments.
We can do it. We have to understand the concepts, but humanists are good at grappling with abstractions. We can use R to handle the calculations. These three posts on R and Burrell provide all we need in order to turn copy counts into an estimation of lost editions along with confidence intervals and a test of goodness of fit. Every part of the more robust approach suggested by Burrell is now implemented in R. We could write a script to automate the whole process. This doesn't solve all our problems - there's the problem of most kinds of book survival not being good fits for a Poisson distribution - but it at least gets us caught up to 2008.
Friday, October 17, 2014
Let's learn R: Estimating what we can't see
How amazing is R? It's so amazing that you can throw some data at it and ask R to fit it to a distribution, and R will do it. So let's take Proot and Egghe's data and throw it at a Poisson distribution (like Burrell suggests). For that, we'll need to use the fitdistr() function from the MASS library:
> require(MASS)
Also, we need to set up a vector filled with Proot and Egghe's data by filling it with 714 ones, 82 twos, and so on:
> x<-rep(1,714)
> x<-c(x,rep(2,82))
> x<-c(x,rep(3,84))
> x<-c(x,rep(4,3))
> x<-c(x,rep(5,1))
Let's make sure it looks right:
> table(x)
x
1 2 3 4 5
714 82 84 3 1
Now we'll tell it to fit the data to a poisson distribution:
> fitdistr(x,"poisson")
lambda
1.29751131
(0.03831153)
Wow! That was easy. So what do 804 data points (the number of editions in Proot and Egghe's sample) look like in a Poisson distribution with a lamda value of 1.2975? It looks like this, which is nothing like our data:
> hist(rpois(804,1.2975))

What went wrong?
Picking up where we left off: What Proot and Egghe are observing is a truncated Poisson distribution: There are 0-copy editions, and we don't know how many--but they also affect the distribution's defining parameter. Burrell's equations (1) and (2) give the formulas for a truncated Poisson distribution and its log-likelihood function, which is needed for determining the formula for a maximum likelihood estimation (or in other words: estimating the missing editions), which Burrell also provides in (3):

This looks impenetrable, but it isn't so bad: Lamda (λ) is the number we're looking for, e is Euler's number (2.718...), and x-bar is just the average number of copies per edition, 907/804 = 1.1281. So all we have to do is solve for λ...which, as Burrell points out, is not possible by using algebra. It can only be estimated numerically. How are we going to do that?
With R, of course. Here's Burrell's equation (3) in R.
> g <- function (lamda) (lamda/(1-exp(1)^-lamda))-907/804
Now that R knows what the equation is, let's tell R to solve it for us. We have to give R a range to look for the root in. We'll try a range between "very small" and 5, since only values above 0 make sense (we could try a range from -1 to 5 for the same result).
> uniroot(g,c(.0001,5))
$root
[1] 0.2461318
$f.root
[1] -2.516872e-07
$iter
[1] 6
$init.it
[1] NA
$estim.prec
[1] 6.103516e-05
And there's λ = .2461, just like Burrell said it would be. Now that we know λ, we can create Burrell's equation (1) and generate some expected values:
> h <- function (r) (((exp(1)^.2461)-1)^-1)*((.2461^r)/factorial(r))
Between the range of 1 and 5, let's see what we would expect to find, given 804 editions:
> h(seq(1:5))*804
[1] 709.12157887 87.25741028 7.15801622 0.44039695 0.02167634
Graphically, it's clear that there's a close match between what we expect to find and what Proot and Egghe's data - note how closely the red and blue dots are:
> range<-seq(1:5)
> y<-h(range)*804
> plot(x,col="red",pch=19);points(range,y,col="blue",pch=19)

This is an important step, as it tells us that we're not completely mistaken in treating Proot and Egghe's data as a truncated Poisson distribution. Burrell also provides a statistical test of goodness of fit, but we'll come back to that later. Now that we know λ, we can calculate the fraction of 0-copy editions with the formula that Burrell provides on p. 103:
 Or in R:
Or in R:
> exp(-.2461)
[1] 0.781844
And there we have it. If there are 804 known editions, then there are 804/(1-.781844) = 3685 missing editions (approximately - we'll look at confidence intervals later).
> 804/(1-exp(-.2461))
[1] 3685.437
So that gives us 3685 + 804 = 4489 total editions. What do we expect a truncated Poisson distribution with a lamda of .2461 and 4489 data points to look like?
> x<-rpois(4489,.2461)
> x<-x[x>0]
> table(x)
x
1 2 3 4
850 109 8 1
> hist(x,breaks=c(0,1,2,3,4))

Now that's more like it:
Next time: Confidence intervals, a quibble with Burrell, and final thoughts.
> require(MASS)
Also, we need to set up a vector filled with Proot and Egghe's data by filling it with 714 ones, 82 twos, and so on:
> x<-rep(1,714)
> x<-c(x,rep(2,82))
> x<-c(x,rep(3,84))
> x<-c(x,rep(4,3))
> x<-c(x,rep(5,1))
Let's make sure it looks right:
> table(x)
x
1 2 3 4 5
714 82 84 3 1
Now we'll tell it to fit the data to a poisson distribution:
> fitdistr(x,"poisson")
lambda
1.29751131
(0.03831153)
Wow! That was easy. So what do 804 data points (the number of editions in Proot and Egghe's sample) look like in a Poisson distribution with a lamda value of 1.2975? It looks like this, which is nothing like our data:
> hist(rpois(804,1.2975))
What went wrong?
Picking up where we left off: What Proot and Egghe are observing is a truncated Poisson distribution: There are 0-copy editions, and we don't know how many--but they also affect the distribution's defining parameter. Burrell's equations (1) and (2) give the formulas for a truncated Poisson distribution and its log-likelihood function, which is needed for determining the formula for a maximum likelihood estimation (or in other words: estimating the missing editions), which Burrell also provides in (3):
This looks impenetrable, but it isn't so bad: Lamda (λ) is the number we're looking for, e is Euler's number (2.718...), and x-bar is just the average number of copies per edition, 907/804 = 1.1281. So all we have to do is solve for λ...which, as Burrell points out, is not possible by using algebra. It can only be estimated numerically. How are we going to do that?
With R, of course. Here's Burrell's equation (3) in R.
> g <- function (lamda) (lamda/(1-exp(1)^-lamda))-907/804
Now that R knows what the equation is, let's tell R to solve it for us. We have to give R a range to look for the root in. We'll try a range between "very small" and 5, since only values above 0 make sense (we could try a range from -1 to 5 for the same result).
> uniroot(g,c(.0001,5))
$root
[1] 0.2461318
$f.root
[1] -2.516872e-07
$iter
[1] 6
$init.it
[1] NA
$estim.prec
[1] 6.103516e-05
And there's λ = .2461, just like Burrell said it would be. Now that we know λ, we can create Burrell's equation (1) and generate some expected values:
> h <- function (r) (((exp(1)^.2461)-1)^-1)*((.2461^r)/factorial(r))
Between the range of 1 and 5, let's see what we would expect to find, given 804 editions:
> h(seq(1:5))*804
[1] 709.12157887 87.25741028 7.15801622 0.44039695 0.02167634
Graphically, it's clear that there's a close match between what we expect to find and what Proot and Egghe's data - note how closely the red and blue dots are:
> range<-seq(1:5)
> y<-h(range)*804
> plot(x,col="red",pch=19);points(range,y,col="blue",pch=19)
This is an important step, as it tells us that we're not completely mistaken in treating Proot and Egghe's data as a truncated Poisson distribution. Burrell also provides a statistical test of goodness of fit, but we'll come back to that later. Now that we know λ, we can calculate the fraction of 0-copy editions with the formula that Burrell provides on p. 103:
> exp(-.2461)
[1] 0.781844
And there we have it. If there are 804 known editions, then there are 804/(1-.781844) = 3685 missing editions (approximately - we'll look at confidence intervals later).
> 804/(1-exp(-.2461))
[1] 3685.437
So that gives us 3685 + 804 = 4489 total editions. What do we expect a truncated Poisson distribution with a lamda of .2461 and 4489 data points to look like?
> x<-rpois(4489,.2461)
> x<-x[x>0]
> table(x)
x
1 2 3 4
850 109 8 1
> hist(x,breaks=c(0,1,2,3,4))
Now that's more like it:
Next time: Confidence intervals, a quibble with Burrell, and final thoughts.
Friday, October 10, 2014
Egenolff, Grünpeck, and list prophecies
The most significant contribution to the formation of a canon of fifteenth- and sixteenth-century German prophecies was probably that of the Frankfurt printer Christian Egenolff the Elder. After a brush with the law in Strasbourg in the early 1530s, Egenolff moved to Frankfurt and became one of the leading publishers of popular vernacular literature. Between 1531 and 1537, Egenolff published a collection of sibylline prophecies, Zwölff Sibyllen Weissagungen, along with some additional material (VD16 Z 941-945). A decade later, Egenolff expanded the collection significantly by adding the work of Johannes Lichtenberger, Johann Carion, and Paracelsus (VD16 P 5065-5066, P 5068). Reprints of both the smaller and the larger collections appear through the end of the sixteenth century and into the seventeenth and even eighteenth centuries.
While working on Printing and Prophecy, I wanted to consult the 1537 edition (VD16 Z 945), but by itself it didn't seem enough to justify a trip to Wolfenbüttel when obtaining a facsimile would be cheaper - but then, after I was back in the U.S., I learned the the condition of the volume was too fragile for the Herzog August Bibliothek to digitize it. Now that I've had a chance to look at it, it turns out to contain a few surprises.
The collection is the first of Egenolff's to include a work by Josef Grünpeck, but it isn't the same work that shows up in the expanded 1548-50 editions (that work, Von der Reformation der Christenheyt und der Kirchen, is known only from the latest Egenolff collections). For the 1537 sibylline collection, Egenolff instead included Grünpeck's Prognosticum of 1532 (VD16 G 3634-3640, ZV 7115, ZV 23147), making the 1537 Egenolff collection the latest edition of that work. Since the Prognosticum didn't foresee much left of the world's future after 1540, Egenolff in 1548 reached farther back to find a more timely work by Grünpeck.
While working on Printing and Prophecy, I wanted to consult the 1537 edition (VD16 Z 945), but by itself it didn't seem enough to justify a trip to Wolfenbüttel when obtaining a facsimile would be cheaper - but then, after I was back in the U.S., I learned the the condition of the volume was too fragile for the Herzog August Bibliothek to digitize it. Now that I've had a chance to look at it, it turns out to contain a few surprises.
The collection is the first of Egenolff's to include a work by Josef Grünpeck, but it isn't the same work that shows up in the expanded 1548-50 editions (that work, Von der Reformation der Christenheyt und der Kirchen, is known only from the latest Egenolff collections). For the 1537 sibylline collection, Egenolff instead included Grünpeck's Prognosticum of 1532 (VD16 G 3634-3640, ZV 7115, ZV 23147), making the 1537 Egenolff collection the latest edition of that work. Since the Prognosticum didn't foresee much left of the world's future after 1540, Egenolff in 1548 reached farther back to find a more timely work by Grünpeck.
The other unusual feature of the 1537 edition is that it claims to include a work by Filippo Cattaneo, identifed as being "vom Thurn auß Italia." Another prognostication attributed to Cattaneo appeared in 1535 (VD16 C 1725) - but that is not the work included by Egenolff in 1537. Instead, the work that appears in the 1537 collection is a set of terse prophecies for 1537-1550. The basic structure is a governing planet and year, the abundance of oil, wine, and grain, and then an additional brief prognostication. For example:
Mon 1537.
Ols wenig
Weins abgang
Treydt wenig
Zwitracht der Fürsten.
The interesting thing is what happens when you look only at the year and last line:
Mon 1537. Zwitracht der Fürsten
Mars 1538. Vil pestilent in allen landen
Mercurius 1539. Krieg undern Christen
Jupiter 1540. Sterben der Fürsten
Saturnus 1541. Frid in allen landen
Sonn 1542. Außbruch der verschlossen juden
Mon 1543. Juden wider die Christen
Mars 1544. Juden von Christen überwunden
Jupiter 1545. Falsche Propheten
Venus 1546. Vil laster und übels
Saturnus 1547. Kranckheyt der Pestilentz
Sonn 1548. Ein heylger man
1549. Wütten der ungleubigen1550. Durch disen heyligen man werden alle unglaubigen zum glauben bekert / Als dann würdt werden ein Schaffstal / ein Hirt / und ein Herr / der die gantze welt under seine Herrschafft bringen und regieren würdt. Unnd als dann würdt das Gülden alter herfür kommen.
This looks to me very much like a predecessor of the list prophecy for 1570-80. Compare "Sterben der Fürsten" with "Pastor non erit," or "Ein heylger man" with "Surget maximus vir," or the culmination in "ein Schaffstal / ein Hirt / und ein Herr" with "unum ovile et unus pastor." All of these are common prophetic tropes, of course, but their combination in a list rather than a narrative suggests there may be some direct influence.
The set of people who are interested in Joseph Grünpeck, Christian Egenolff, and the list prophecy for 1570-80 may be somewhat restricted. But for those people, VD16 Z 945 is an extremely interesting edition.
Friday, September 26, 2014
Let's learn R: Burrell on the binomial distribution
With this post, we'll start using R to retrace the steps of Quentin L. Burrell's article, "Some Comments on 'The Estimation of Lost Multi-Copy Documents: A New Type of Informetrics Theory' by Egghe and Proot," and
translate it from the language of statistics into the language of the
humanities.
Burrell's first important point (102) is:
What does this mean, and why does it matter?
Burrell is responding to Proot and Egghe's formula for estimating lost editions, and they use a formula for the binomial distribution as their basis for their work. Burrell is restating a basic fact from statistics: For a data set where the number of attempts at success is large and the chance of success is small, the data will tend to fit not only a binomial distribution but also a Poisson distribution, which has some useful features for the kind of analysis he will be doing later. Where a binomial distribution has two parameters, the number of trials and the chance of success (n and θ, respectively), a Poisson distribution has only one parameter, its mean (or λ).
Is n large? In this case, yes, since n is the number of copies of each Jesuit play program that were printed. Although n isn't the same for every play program, it's a safe assumption that it's at least 150 or more, so the difference in print runs ends up not making much difference (as Proot and Egghe show in their article).
Is θ small? In this case, yes, since θ represents the likelihood of a copy to survive. With at most 5 copies of each edition surviving, θ is probably no higher than somewhere in the neighborhood of .02, and much lower for editions for fewer or no surviving copies.
So in these circumstances, can we approximate a binomial distribution with a Poisson distribution? Let's use R to illustrate how it works.
One thing that R makes quite easy is generating random data that follows a particular distribution. Let's start with 3500 observations (or, we might say, editions originally printed), with 250 trials in each (or copies of each edition that might survive) and a very low probability that any particular copy will survive, or .002. In R, we can simulate this as
> x <- rbinom (3500, 250, .002)
In other words, fill up the vector x with 3500 random points that follow a binomial distribution. What does it look like?
> hist (x)

Now let's compare random points that follow Poisson distribution. We want 3500 data points again, and we also need to provide a value for λ. Since we want to see if λ really is equal to nθ, we'll use 250*.002 or .5 for λ.
> y <- rpois (3500,.5)
Let's see what the result looks like:
> hist (y)

If you look very closely, you can see that the histograms are very similar but not quite identical - which you would expect for 3500 points chosen at random.
Our data sets only have whole-number values, so let's make the histograms reflect that:
> hist (x, breaks=c(0,1,2,3,4,5))

> hist (y, breaks=c(0,1,2,3,4,5))

Let's compare the two sets of values to see how close they are. Whenever we create a histogram, R automatically creates some information about that histogram. Let's access it:
> xinfo <- hist (x, breaks=c(0,1,2,3,4,5))
> yinfo <- hist (y, breaks=c(0,1,2,3,4,5))
Typing xinfo results in a lot of useful information, but we specifically want the counts. We could type xinfo$counts, but we want to view our data in a nice table. So let's try this:
> table <- data.frame (xinfo$counts, yinfo$counts, row.names=c(0,1,2,3,4))
(We gave the table the row names of 0-4, because otherwise the row name for zero observations would be "1," and the row name for one observation would be "2," and so on, which would be confusing.) Typing table results in this:
xinfo.counts yinfo.counts
0 3204 3208
1 252 245
2 37 41
3 6 5
4 1 1
So there you have it. For the material Proot and Egghe are dealing with, a Poisson distribution will work as well as a binomial distribution. Next time: truncated distributions, or what happens when you don't know how many editions you have to begin with.
Burrell's first important point (102) is:
A binomial distribution Bin(n, θ) with n large and θ small can be approximated by a Poisson distribution with mean λ = nθ.
What does this mean, and why does it matter?
Burrell is responding to Proot and Egghe's formula for estimating lost editions, and they use a formula for the binomial distribution as their basis for their work. Burrell is restating a basic fact from statistics: For a data set where the number of attempts at success is large and the chance of success is small, the data will tend to fit not only a binomial distribution but also a Poisson distribution, which has some useful features for the kind of analysis he will be doing later. Where a binomial distribution has two parameters, the number of trials and the chance of success (n and θ, respectively), a Poisson distribution has only one parameter, its mean (or λ).
Is n large? In this case, yes, since n is the number of copies of each Jesuit play program that were printed. Although n isn't the same for every play program, it's a safe assumption that it's at least 150 or more, so the difference in print runs ends up not making much difference (as Proot and Egghe show in their article).
Is θ small? In this case, yes, since θ represents the likelihood of a copy to survive. With at most 5 copies of each edition surviving, θ is probably no higher than somewhere in the neighborhood of .02, and much lower for editions for fewer or no surviving copies.
So in these circumstances, can we approximate a binomial distribution with a Poisson distribution? Let's use R to illustrate how it works.
One thing that R makes quite easy is generating random data that follows a particular distribution. Let's start with 3500 observations (or, we might say, editions originally printed), with 250 trials in each (or copies of each edition that might survive) and a very low probability that any particular copy will survive, or .002. In R, we can simulate this as
> x <- rbinom (3500, 250, .002)
In other words, fill up the vector x with 3500 random points that follow a binomial distribution. What does it look like?
> hist (x)
Now let's compare random points that follow Poisson distribution. We want 3500 data points again, and we also need to provide a value for λ. Since we want to see if λ really is equal to nθ, we'll use 250*.002 or .5 for λ.
> y <- rpois (3500,.5)
Let's see what the result looks like:
> hist (y)
If you look very closely, you can see that the histograms are very similar but not quite identical - which you would expect for 3500 points chosen at random.
Our data sets only have whole-number values, so let's make the histograms reflect that:
> hist (x, breaks=c(0,1,2,3,4,5))
> hist (y, breaks=c(0,1,2,3,4,5))
Let's compare the two sets of values to see how close they are. Whenever we create a histogram, R automatically creates some information about that histogram. Let's access it:
> xinfo <- hist (x, breaks=c(0,1,2,3,4,5))
> yinfo <- hist (y, breaks=c(0,1,2,3,4,5))
Typing xinfo results in a lot of useful information, but we specifically want the counts. We could type xinfo$counts, but we want to view our data in a nice table. So let's try this:
> table <- data.frame (xinfo$counts, yinfo$counts, row.names=c(0,1,2,3,4))
(We gave the table the row names of 0-4, because otherwise the row name for zero observations would be "1," and the row name for one observation would be "2," and so on, which would be confusing.) Typing table results in this:
xinfo.counts yinfo.counts
0 3204 3208
1 252 245
2 37 41
3 6 5
4 1 1
So there you have it. For the material Proot and Egghe are dealing with, a Poisson distribution will work as well as a binomial distribution. Next time: truncated distributions, or what happens when you don't know how many editions you have to begin with.
Friday, September 12, 2014
Let's learn R: histograms for the humanities
To avoid all misunderstanding, let me make two things completely clear at the beginning: I don't know statistics and I don't know R. I did a math minor as an undergraduate, and I like to experiment with software that looks like it might be useful. That's all. Comments and corrections are welcome.
But it's been clear to me for some time that several research problems in the humanities have statistical implications, or could be productively addressed through statistical methods, and the gradually rising profile of the digital humanities will likely make statistical methods increasingly useful.
Estimating the number of lost incunable editions is one example of a research problem that required statistical expertise. For that, Paul Needham and I partnered with Frank McIntyre, an econometrician now at Rutgers. But I can't bug Frank every time I have a statistics question. He actually has to work in his own field now and again. Even when we're working on a project together, I need to understand his part enough to ask intelligent questions about it, but I haven't been able to retrace his steps, or the steps of any other statistician.
This is where R comes in. R is a free and open source statistical software package with a thriving developer community. I've barely scratched the surface of it, but I can already see that R makes some things very easy that are difficult without it.
Like histograms. Histograms are simply graphs of how many items fit into some numerical category. If you have a long list of books and the years they were printed, how many were printed in the 1460s, 1470s, or 1480s? Histograms represent data in a way that is easy to grasp. If you've ever tried it, however, you know that histograms are a huge pain to make in Excel (and real statisticians complain about the result in any case).
To illustrate how easy it is in R, let's turn again to Eric White's compilation of known print runs of fifteenth-century books. Here's how to make the following histogram in R:
> hist (printrun)
It really is that fast and simple.
Of course, there are a few additional steps that go into it. First, we need some data. We could put our data in a simple text file (named data.txt for this example) and open the text file. On Windows, R looks for files by default in the Documents library directory. If we only include the print runs in the text file, then R will number each row and assign a column header automatically.
To read the file into R, we need to assign it to a vector, which we'll call x:
> x <- read.table ("data.txt")
If we want to use our own column header, then we need to specify it:
> x <- read.table ("data.txt", col.names="printrun")
But my data is already a column in an Excel spreadsheet with the column header printrun, so I can just copy the column and paste it into R with the following command (on Windows) that tells R to read from the clipboard and make the first thing it finds a column header rather than data:
> x <- read.table ("clipboard", header=TRUE)
To see what's now in x, you just need to type
> x
and the whole thing will be printed out on screen. We can now access the print runs by referring to that column as x$printrun, but it might simplify the process by telling R to keep the table and its variables - its column headers, in other words - in mind:
> attach (x)
At this point, we can start playing with histograms by issuing the command hist (printrun) as above. To see all our options, we can get the help page by typing
> ?hist
The first histogram is nice, but I would really like to have solid blue bars outlined in black:
> hist (printrun, col="blue", border="black")

The hist() command uses an algorithm to determine sensible bin widths, or how wide each column is. But 500 seems too wide to me, so let's specify something else. If I want bin widths of 250, I could specify the number of breaks as twenty:
> hist (printrun, col="blue",border="black", breaks=20)

Last time, I used bin widths of 135 and found a bimodal distribution. To do that again, I'll need to specify a range of 0 to 5130 (which is 38 * 135):
> hist (printrun, col="blue",border="black", breaks=seq (0, 5130, by=135))

To generate all the images for this post, I told R to output PNG files (it also can do TIFFs, JPGs, BMPs, PDFs, and other file types, including print-quality high resolution images, and there are also label and formatting options that I haven't mentioned here).
> png ()
> hist (printrun)
> hist (printrun, col="blue", border="black")
> hist (printrun, col="blue",border="black", breaks=20)
> hist (printrun, col="blue",border="black", breaks=seq (0, 5130, by=135))
> dev.off ()
It's as simple as that. Putting high-powered tools for statistical analysis into the hands of humanities faculty. What could possibly go wrong?
I have a few more posts about using R, but it may be a few weeks before the next one, as I'll be traveling for two conferences in the next several weeks. Next time, I'll start using R to retrace the steps of Quentin L. Burrell's article, "Some Comments on 'The Estimation of Lost Multi-Copy Documents: A New Type of Informetrics Theory' by Egghe and Proot," Journal of Informetrics 2 (January 2008): 101–5. It's an important article, and R can help us translate it from the language of statistics into the language of the humanities.
But it's been clear to me for some time that several research problems in the humanities have statistical implications, or could be productively addressed through statistical methods, and the gradually rising profile of the digital humanities will likely make statistical methods increasingly useful.
Estimating the number of lost incunable editions is one example of a research problem that required statistical expertise. For that, Paul Needham and I partnered with Frank McIntyre, an econometrician now at Rutgers. But I can't bug Frank every time I have a statistics question. He actually has to work in his own field now and again. Even when we're working on a project together, I need to understand his part enough to ask intelligent questions about it, but I haven't been able to retrace his steps, or the steps of any other statistician.
This is where R comes in. R is a free and open source statistical software package with a thriving developer community. I've barely scratched the surface of it, but I can already see that R makes some things very easy that are difficult without it.
Like histograms. Histograms are simply graphs of how many items fit into some numerical category. If you have a long list of books and the years they were printed, how many were printed in the 1460s, 1470s, or 1480s? Histograms represent data in a way that is easy to grasp. If you've ever tried it, however, you know that histograms are a huge pain to make in Excel (and real statisticians complain about the result in any case).
To illustrate how easy it is in R, let's turn again to Eric White's compilation of known print runs of fifteenth-century books. Here's how to make the following histogram in R:
> hist (printrun)
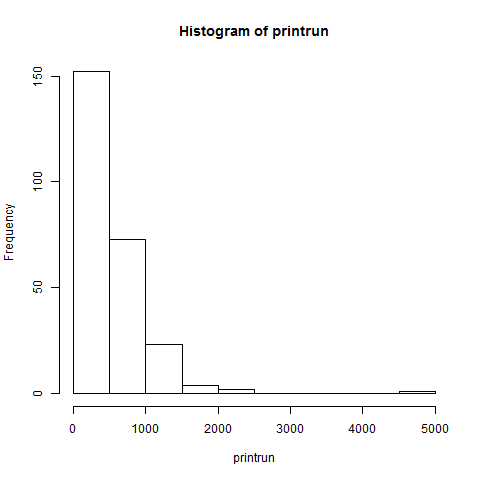
It really is that fast and simple.
Of course, there are a few additional steps that go into it. First, we need some data. We could put our data in a simple text file (named data.txt for this example) and open the text file. On Windows, R looks for files by default in the Documents library directory. If we only include the print runs in the text file, then R will number each row and assign a column header automatically.
To read the file into R, we need to assign it to a vector, which we'll call x:
> x <- read.table ("data.txt")
If we want to use our own column header, then we need to specify it:
> x <- read.table ("data.txt", col.names="printrun")
But my data is already a column in an Excel spreadsheet with the column header printrun, so I can just copy the column and paste it into R with the following command (on Windows) that tells R to read from the clipboard and make the first thing it finds a column header rather than data:
> x <- read.table ("clipboard", header=TRUE)
To see what's now in x, you just need to type
> x
and the whole thing will be printed out on screen. We can now access the print runs by referring to that column as x$printrun, but it might simplify the process by telling R to keep the table and its variables - its column headers, in other words - in mind:
> attach (x)
At this point, we can start playing with histograms by issuing the command hist (printrun) as above. To see all our options, we can get the help page by typing
> ?hist
The first histogram is nice, but I would really like to have solid blue bars outlined in black:
> hist (printrun, col="blue", border="black")
The hist() command uses an algorithm to determine sensible bin widths, or how wide each column is. But 500 seems too wide to me, so let's specify something else. If I want bin widths of 250, I could specify the number of breaks as twenty:
> hist (printrun, col="blue",border="black", breaks=20)
Last time, I used bin widths of 135 and found a bimodal distribution. To do that again, I'll need to specify a range of 0 to 5130 (which is 38 * 135):
> hist (printrun, col="blue",border="black", breaks=seq (0, 5130, by=135))
To generate all the images for this post, I told R to output PNG files (it also can do TIFFs, JPGs, BMPs, PDFs, and other file types, including print-quality high resolution images, and there are also label and formatting options that I haven't mentioned here).
> png ()
> hist (printrun)
> hist (printrun, col="blue", border="black")
> hist (printrun, col="blue",border="black", breaks=20)
> hist (printrun, col="blue",border="black", breaks=seq (0, 5130, by=135))
> dev.off ()
It's as simple as that. Putting high-powered tools for statistical analysis into the hands of humanities faculty. What could possibly go wrong?
* * *
I have a few more posts about using R, but it may be a few weeks before the next one, as I'll be traveling for two conferences in the next several weeks. Next time, I'll start using R to retrace the steps of Quentin L. Burrell's article, "Some Comments on 'The Estimation of Lost Multi-Copy Documents: A New Type of Informetrics Theory' by Egghe and Proot," Journal of Informetrics 2 (January 2008): 101–5. It's an important article, and R can help us translate it from the language of statistics into the language of the humanities.
Friday, September 5, 2014
Abstract: "Bibliographic databases and early printing: Questions we can’t answer and questions we can’t ask"
For the upcoming meeting of the Wolfenbütteler Arbeitskreises für Bibliotheks-, Buch- und Mediengeschichte on the topic of book history and digital humanities, the paper I'm giving will briefly summarize the paper I gave at the "Lost Books" conference in June, then look specifically at the bibliographical databases of early printing that we have today. These databases are invaluable, but their current design makes some kinds of research easy and other kinds quite difficult. Along with charts and graphs, my presentation will look at some specific examples of what can and can't be done at the moment, and offer some suggestions of what might be done in the future.
Abstract: Bibliographic databases and early printing: Questions we can’t answer and questions we can’t ask.
In 1932, Ernst Consentius first proposed addressing the question of how many incunable editions have been lost by graphing the number of editions preserved in a few copies or just one and projecting an estimate based on that graph. The problem Consentius posed is in fact only a variation of a problem that can be found in many academic fields, known in English since 1943 as the “unseen species problem,” although it has not been recognized as such until very recently. Using the well-established statistical methods and tools for approaching the unseen species problem, I and Frank McIntyre have recently updated the estimate that we first published in 2010. Depending on the assumptions used, our new estimate is that between 33% (of all editions) and 49% (of codex editions, plus an indeterminate but large number of broadsides) have been lost.
The problem of estimating lost editions exemplifies how data-drive approaches can support book history, but it also illustrates how databases of early printing impose limits on research in the way they structure their records and in the user interfaces by which they make data available. Of the current database projects relevant for early printing in Germany (GW, ISTC, VD16, VD17, and USTC), each has particular advantages in the kinds of data it offers, but also particular disadvantages in how it permits that data to be searched and accessed. Clarity and consistency of formatting would help in some cases. All of the databases could profit by adding information that only one or none of the databases currently provide, such as leaf counts. User interfaces should reveal more of each database’s fields, rather than making them only implicitly visible through search results. Monolithic imprint lines, particularly those that make use of arcane or archaic terminology, must be replaced by explicit differentiation of printers and publishers.
Of the current databases, the technological advantages of VD16 are often overlooked. Its links from editions to a separate listing of shelf marks makes it possible to count copies more simply and accurately than any other database, and its links from authors’ names to an external authority file of biographical data provide the basis for characterizing the development of printing in the sixteenth century. Most importantly, VD16 provides open access to its MARC-formatted records, allowing an unequaled ease and accuracy when analyzing records of sixteenth-century printing. Many VD16 records lack information about such basic information as their language, however.
The missing language fields in VD16 provide an example of the challenges faced in attempting to compare bibliographic data across borders or centuries. One approach to this problem, taken by the USTC as a database of databases, is to offer relatively sparse data to users. I suggest as an alternative to this a different approach: Databases should open their data to contributions from and analysis by scholars all over the world by making their records freely available. Doing so will allow scholars of book history to pursue data-driven approaches to questions in our field.
Friday, August 29, 2014
The Strange and Terrible Visions of Wilhelm Friess, Chapter Seven: The Last Emperor and the Beginning of Prophecy
The last chapter of The Strange and Terrible Visions does three things. First, it wraps up the argument about how the two prophecies of Wilhelm Friess are connected. Rather than the same name being used arbitrarily for two different texts published twenty years apart, "Friess II" is connected to "Friess I" by a chain of textual influence and historical context where the links are separated by just a few years, rather than a few decades: Basel editions beginning in 1577 of a text grounded in the situation of Strasbourg's Reformed community in 1574 based on historical resonance with Reformed civic unrest in Antwerp in 1567 and in reaction to a specifically Lutheran branch of "Friess I" which was circulating in the Netherlands in 1566.
The second item of interest involves taking a look at late appearances of the prophecies of Wilhelm Friess. "Friess II" is interesting because the latest edition, published in 1639 as the Thirty Years' War was giving new relevance to a prophecy about foreign armies laying waste to Germany, reflects an earlier stage of the text than any other edition. "Friess I" reappears even later, in several editions of 1686-91, when Louis XIV's annexation of Strasbourg made him a prime candidate for the tyrannical Antichrist of the west.
Finally, I suggest four characteristic ways that prophetic texts develop:
The second item of interest involves taking a look at late appearances of the prophecies of Wilhelm Friess. "Friess II" is interesting because the latest edition, published in 1639 as the Thirty Years' War was giving new relevance to a prophecy about foreign armies laying waste to Germany, reflects an earlier stage of the text than any other edition. "Friess I" reappears even later, in several editions of 1686-91, when Louis XIV's annexation of Strasbourg made him a prime candidate for the tyrannical Antichrist of the west.
Finally, I suggest four characteristic ways that prophetic texts develop:
- Selective reception of an earlier prophecy
- Expansion into a complete prophecy
- A historical context that requires veiling the message
- Adaptation to a new context
Friday, August 15, 2014
Adding an author to a fragmentary incunable prognostication
Identifying the author of a fragmentary annual prognostication is sometimes difficult, requiring a significant amount of research. Other times, it only takes a few minutes.
This week, the Heidelberg university library released a facsimile of ISTC ip01005937/GW M35611, a fairly extensive fragment that is lacking an incipit, so no author had been identified. Leaf 1v did provide a complete list of chapters, however, and the structure looked familiar. After checking my records, I found that the text of the fragment was identical to that of another incucanble edition: Bernardinus de Luntis, Judicium for 1492 (Rome: Stephan Plannck, [around 1492]; ISTC il00392200, GW M19510). The identity of the two texts can be verified by comparing the facsimile provided by the BSB, so Bernardinus de Luntis should be added as the author to ISTC ip01005937/GW M35611. I sent a note on to Berlin to that effect.
Bernardinus de Luntis is otherwise known to ISTC/GW only through one additional practica, for 1493: ISTC il00392300/GW M19511, again printed by Stephan Plannck. It's not unusual for astrologers to have a career in print that only lasted a few years, but the distribution of surviving copies is a bit odd in this case: apart from one copy in the Vatican, the other three are all in German-speaking Europe, in Basel, Heidelberg, and Munich. Apart from a brief mention by Simon de Phares in his Recueil des plus célèbres astrologues, not much appears to be known about Bernardinus de Luntis.
Update: Klaus Graf adds a few more references to Bernardinus de Luntis here.
This week, the Heidelberg university library released a facsimile of ISTC ip01005937/GW M35611, a fairly extensive fragment that is lacking an incipit, so no author had been identified. Leaf 1v did provide a complete list of chapters, however, and the structure looked familiar. After checking my records, I found that the text of the fragment was identical to that of another incucanble edition: Bernardinus de Luntis, Judicium for 1492 (Rome: Stephan Plannck, [around 1492]; ISTC il00392200, GW M19510). The identity of the two texts can be verified by comparing the facsimile provided by the BSB, so Bernardinus de Luntis should be added as the author to ISTC ip01005937/GW M35611. I sent a note on to Berlin to that effect.
Bernardinus de Luntis is otherwise known to ISTC/GW only through one additional practica, for 1493: ISTC il00392300/GW M19511, again printed by Stephan Plannck. It's not unusual for astrologers to have a career in print that only lasted a few years, but the distribution of surviving copies is a bit odd in this case: apart from one copy in the Vatican, the other three are all in German-speaking Europe, in Basel, Heidelberg, and Munich. Apart from a brief mention by Simon de Phares in his Recueil des plus célèbres astrologues, not much appears to be known about Bernardinus de Luntis.
Update: Klaus Graf adds a few more references to Bernardinus de Luntis here.
Friday, August 8, 2014
Abstract: "And also upon the servants and upon the handmaids: Illiteracy and the struggle for authority in the lost visions of Lienhard Jost"
This is the abstract I submitted for the paper I'll be giving at the annual conference of the German Studies Association in September in the session "Prophecy and Identity in Medieval and Early Modern Germany." It's based on a paper that was recently accepted by Sixteenth Century Studies, although it may not be in print until next fall or later. This is the first time in several years that I'm dealing not just with a prophetic text but with an actual visionary as a source. I'm excited about this project, as I think it might point in some interesting new directions, not specifically at the Strasbourg prophets (it sounds like Christina Moss, a doctoral student at Waterloo, will do that in her dissertation, which I'm looking forward to seeing). Instead, I think the case of Lienhard Jost might just point towards a general theory of prophecy, from vision to text to excerpt to literary allusion.
In any case, here's the abstract.
In any case, here's the abstract.
Abstract: "And also upon the servants and upon the handmaids: Illiteracy and the struggle for authority in the lost visions of Lienhard Jost"
Lienhard Jost is recognized today as one of the leading members of the Strasbourg Prophets associated with Melchior Hoffman in the 1530s. Because Jost’s works have been lost for centuries, however, basic facts of his biography have been uncertain, and he has been treated as a secondary figure behind Hoffman and behind his visionary wife Ursula Jost. With the rediscovery of Lienhard Jost’s visions in a copy preserved in Vienna, we now have access to a unique account in his own words of the experiences of an early modern German folk prophet. Jost’s visions, published by Melchior Hoffman in 1532, establish that he was an illiterate woodcutter. Popular accounts of learned discourse, including the Reformation and predictions of a second deluge in 1524, inspired Jost’s prophetic experiences. Jost’s account of his visions documents his progressive transformation with respect to literacy. At the beginning of his preaching, Jost regarded the written word as a silencing of and a loss of control over his own speech. Jost’s prophecies included not only oral preaching but also active performance of his message. In Jost’s account, these prophetic episodes transformed the city’s insane asylum, where he was confined, into a school. Although still illiterate when released, Jost saw himself as now authorized to comment on scripture and engage in other textual activities typically reserved for the learned, and he became increasingly confident in having his visions committed to writing and ultimately to print.
Friday, August 1, 2014
The Strange and Terrible Visions of Wilhelm Friess, Chapter Six: Wilhelm Friess in Strasbourg
This is the chapter that's going to get me into trouble. There are some things that prudent scholars of the sixteenth century do not engage in, and that includes attributing anonymous pamphlets to famous writers based on circumstantial evidence. What was I thinking?
The line of thought, from the basic evidence to the crime of wanton attribution, goes like this:
The early textual history of "Friess II" identifies 24 April 1574 as the first alleged date of the vision. Another passage found only in the earliest versions gives special significance to Strasbourg for the survivors of German's future devastation. Another passage attacking Lutheran clergy, the prophecy's attitude towards sacramental theology, and its situating of the source of salvation in the south - in Switzerland - point to an ideological home among the embattled Reformed community of Strasbourg in late spring of 1574. I argue that the demonic child-eating general from the northwest in "Friess II" was meant as a reference to Henry of Valois, king of Poland and until recently a leader of the French anti-Huguenot army and, upon the death of his brother, the presumed next king of France (where he reigned as Henry III).
The dating of "Friess II" is supported by the title page illustration of an early edition, whose eclipsed sun and moon, and conjunction and opposition involving Mars, Saturn, and Mercury, again points to 1574. The zodiacal iconography of Mars, Saturn, and Mercury is also featured prominently in the text of the prophecy. In the spring of 1574, eclipses and conjunctions and anthropomorphic planets took a notable form in Strasbourg with the completion of the cathedral's astronomical clock. The first solar and lunar eclipse on the clock's tables of eclipses are the same ones featured on the title woodcut (which is also the title illustration for The Strange and Terrible Visions of Wilhelm Friess).
As it turns out, the laudatory verse that accompanies a broadside illustration of the new clock was written by Johann Fischart, one of the leading German writers and the most accomplished satirist of the later sixteenth century. Fischart was a native of Strasbourg and a Reformed sympathizer who had earlier written some intemperate things about sacramental theology, supported the Huguenots and the Reformed of the Netherlands, had passed through Flanders at the time "Friess I" was circulating there, was known to publish works anonymously, and had knowledge of astrological and prophetic pamphlets.
That's a pretty amazing coincidence, I told myself. Maybe somebody could argue that Fischart was the author of "Friess II." Maybe I could even say what the evidence would be and what the argument would look like, if someone wanted to make that argument.
In the end, I decided the best approach was not to sketch out what a hypothetical argument might look like, but to simply make the claim that Fischart was the author, and defend that claim as forthrightly as possible. I try not to be irresponsible about it: As with other uncertain points, I give the evidence for both sides (including the not inconsequential note that one expert on Fischart finds the idea entirely ridiculous), and I avoid making Fischart's authorship of "Friess II" essential to any of my other arguments, but this time I opted to take the underdog bet.
The line of thought, from the basic evidence to the crime of wanton attribution, goes like this:
The early textual history of "Friess II" identifies 24 April 1574 as the first alleged date of the vision. Another passage found only in the earliest versions gives special significance to Strasbourg for the survivors of German's future devastation. Another passage attacking Lutheran clergy, the prophecy's attitude towards sacramental theology, and its situating of the source of salvation in the south - in Switzerland - point to an ideological home among the embattled Reformed community of Strasbourg in late spring of 1574. I argue that the demonic child-eating general from the northwest in "Friess II" was meant as a reference to Henry of Valois, king of Poland and until recently a leader of the French anti-Huguenot army and, upon the death of his brother, the presumed next king of France (where he reigned as Henry III).
The dating of "Friess II" is supported by the title page illustration of an early edition, whose eclipsed sun and moon, and conjunction and opposition involving Mars, Saturn, and Mercury, again points to 1574. The zodiacal iconography of Mars, Saturn, and Mercury is also featured prominently in the text of the prophecy. In the spring of 1574, eclipses and conjunctions and anthropomorphic planets took a notable form in Strasbourg with the completion of the cathedral's astronomical clock. The first solar and lunar eclipse on the clock's tables of eclipses are the same ones featured on the title woodcut (which is also the title illustration for The Strange and Terrible Visions of Wilhelm Friess).
As it turns out, the laudatory verse that accompanies a broadside illustration of the new clock was written by Johann Fischart, one of the leading German writers and the most accomplished satirist of the later sixteenth century. Fischart was a native of Strasbourg and a Reformed sympathizer who had earlier written some intemperate things about sacramental theology, supported the Huguenots and the Reformed of the Netherlands, had passed through Flanders at the time "Friess I" was circulating there, was known to publish works anonymously, and had knowledge of astrological and prophetic pamphlets.
That's a pretty amazing coincidence, I told myself. Maybe somebody could argue that Fischart was the author of "Friess II." Maybe I could even say what the evidence would be and what the argument would look like, if someone wanted to make that argument.
In the end, I decided the best approach was not to sketch out what a hypothetical argument might look like, but to simply make the claim that Fischart was the author, and defend that claim as forthrightly as possible. I try not to be irresponsible about it: As with other uncertain points, I give the evidence for both sides (including the not inconsequential note that one expert on Fischart finds the idea entirely ridiculous), and I avoid making Fischart's authorship of "Friess II" essential to any of my other arguments, but this time I opted to take the underdog bet.
Wednesday, July 23, 2014
All sheets are not created equal
At the recent Lost Books conference in St Andrews, a topic that came up during discussion was "survival of the fattest": Books with more leaves tend to survive in greater numbers of copies that thinner books. The USTC apparently has plans to include the number of sheets used in the production of each edition.
The number of sheets is useful, but not quite the key information that one would hope it would be. As Frank McIntyre and I were preparing our paper, we originally considered sheet counts as a way to to enable comparison between formats. If you fold a sheet in half for a folio, or in four for a quarto, or in eight for an octavo, should be of no concern: a sheet is a sheet is a sheet.
Alas, it is not so. When it comes to book survival, how that sheet gets folded matters, as format is still the single most important variable in book survival.
For example, consider books of 8-16 sheets, including folios of 17-32 leaves, quartos of 33-64 leaves, and octavos of 65-128 leaves. Those are thin folios, handy quartos, and thick little octavos, but all composed of the same number of sheets. (Ideally, we would also factor in paper sizes, but that will have to wait for another generation of bibliographic databases.)
If we graph the percentage of incunable editions that survive in a given number of copies, this is what we find:

Despite all having 8-16 sheets, 12% of these folios survive in a single copy, while 20% of the quartos and nearly 30% of the octavos are known by just one copy. Book format informed choices about production, use, and survival more than leaf count did, and in a way that can't be reduced to a simple matter of bulk.
The number of sheets is useful, but not quite the key information that one would hope it would be. As Frank McIntyre and I were preparing our paper, we originally considered sheet counts as a way to to enable comparison between formats. If you fold a sheet in half for a folio, or in four for a quarto, or in eight for an octavo, should be of no concern: a sheet is a sheet is a sheet.
Alas, it is not so. When it comes to book survival, how that sheet gets folded matters, as format is still the single most important variable in book survival.
For example, consider books of 8-16 sheets, including folios of 17-32 leaves, quartos of 33-64 leaves, and octavos of 65-128 leaves. Those are thin folios, handy quartos, and thick little octavos, but all composed of the same number of sheets. (Ideally, we would also factor in paper sizes, but that will have to wait for another generation of bibliographic databases.)
If we graph the percentage of incunable editions that survive in a given number of copies, this is what we find:
Despite all having 8-16 sheets, 12% of these folios survive in a single copy, while 20% of the quartos and nearly 30% of the octavos are known by just one copy. Book format informed choices about production, use, and survival more than leaf count did, and in a way that can't be reduced to a simple matter of bulk.
Friday, June 6, 2014
The Strange and Terrible Visions of Wilhelm Friess, Chapter Five: A Horrible and Shocking Prophecy
As you can see from the sidebar, The Strange and Terrible Visions of Wilhelm Friess is now in print. The book was the result, among other things, of trying to figure out what connected two sets of prophetic pamphlets that appeared to have nothing in common and were separated by two decades, although both claimed to have been found with Wilhelm Friess of Maastricht after his recent death. I answer that question in chapter 5.
The first part of the answer is that the second prophecy ("Friess II"), a desolate vision of utter devastation about to be visited on Germany in the form of demonic armies invading from all sides, shares a few details specifically with the Lübeck editions of "Friess I." Also, I argue that one of the two Lübeck editions has been misdated. While the first of them, VD16 F 2844, is dated in VD16 to 1558, there is strong evidence that it dates to 1566, as nearly all references to years earlier than that have been removed or increased by eight years. In addition, the titles of the Lübeck editions are nearly identical to a lost Dutch edition printed in 1566, last seen at auction over 200 years ago. The best guide to the text it contained is found in the Lübeck editions of Johann Balhorn the Elder.
So not only do we have a version of "Friess I" circulating in the Netherlands and Northern Germany in 1566-68, but it appears to be a specifically Lutheran text. The enemies list that appears in these editions distances itself from Catholics, Anabaptists, and Sacramentarians - that is, from Calvinists. It also condemns insurrection more harshly than other versions of "Friess II," foreseeing that some people will rise up and pillage churches, but the authorities will eradicate them. The setting that gave rise to this version of "Friess I" thus appears to be Dutch Lutheranism at the time of the Dutch Revolt in 1566.
I argue that "Friess II" is a specifically Calvinist reaction to the specifically Lutheran "Friess I" pamphlets circulating in the late 1560s. I suggest that one specific catalyzing even was the Calvinist uprising in Antwerp that ended in a humiliating stand-down after the Calvinists found themselves surrounded on all sides in the city by a force consisting of both Catholics and Lutherans and representatives of Antwerp's merchant community from all the nations of Europe, a source of resentment for many years to come. "Friess II" thus recapitulates as a nightmare vision for Germany the hopeless strategic situation that the Calvinists of Antwerp found themselves in in March 1567.
While the earliest dated editions of "Friess II" were printed by Samuel Apiarius of Basel in 1577, some textual-critical detective work points to an origin in 1574 with a Calvinist sympathizer in Strasbourg, but I treat most of the Strasbourg context in the next chapter.
Due to conference presentations and summer travel, blog updates may be sporadic for a while.
The first part of the answer is that the second prophecy ("Friess II"), a desolate vision of utter devastation about to be visited on Germany in the form of demonic armies invading from all sides, shares a few details specifically with the Lübeck editions of "Friess I." Also, I argue that one of the two Lübeck editions has been misdated. While the first of them, VD16 F 2844, is dated in VD16 to 1558, there is strong evidence that it dates to 1566, as nearly all references to years earlier than that have been removed or increased by eight years. In addition, the titles of the Lübeck editions are nearly identical to a lost Dutch edition printed in 1566, last seen at auction over 200 years ago. The best guide to the text it contained is found in the Lübeck editions of Johann Balhorn the Elder.
So not only do we have a version of "Friess I" circulating in the Netherlands and Northern Germany in 1566-68, but it appears to be a specifically Lutheran text. The enemies list that appears in these editions distances itself from Catholics, Anabaptists, and Sacramentarians - that is, from Calvinists. It also condemns insurrection more harshly than other versions of "Friess II," foreseeing that some people will rise up and pillage churches, but the authorities will eradicate them. The setting that gave rise to this version of "Friess I" thus appears to be Dutch Lutheranism at the time of the Dutch Revolt in 1566.
I argue that "Friess II" is a specifically Calvinist reaction to the specifically Lutheran "Friess I" pamphlets circulating in the late 1560s. I suggest that one specific catalyzing even was the Calvinist uprising in Antwerp that ended in a humiliating stand-down after the Calvinists found themselves surrounded on all sides in the city by a force consisting of both Catholics and Lutherans and representatives of Antwerp's merchant community from all the nations of Europe, a source of resentment for many years to come. "Friess II" thus recapitulates as a nightmare vision for Germany the hopeless strategic situation that the Calvinists of Antwerp found themselves in in March 1567.
While the earliest dated editions of "Friess II" were printed by Samuel Apiarius of Basel in 1577, some textual-critical detective work points to an origin in 1574 with a Calvinist sympathizer in Strasbourg, but I treat most of the Strasbourg context in the next chapter.
* * *
Due to conference presentations and summer travel, blog updates may be sporadic for a while.
Subscribe to:
Posts (Atom)